MV4-11
Target ID: CHEMBL613835
Organism: Homo sapiens
Type: CELL-LINE
Molecules
| Name | SMILES | Bioactivity | Structure |
|---|---|---|---|
| METHOTREXATE | CN(Cc1cnc2nc(N)nc(N)c2n1)c1ccc(C(=O)N[C@@H](CCC(=O)O)C(=O)O)cc1 | ID50: 6.2 nM | 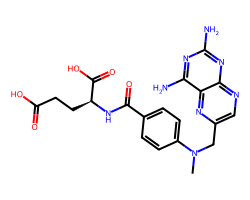 |
| TANDUTINIB | COc1cc2c(N3CCN(C(=O)Nc4ccc(OC(C)C)cc4)CC3)ncnc2cc1OCCCN1CCCCC1 | IC50: 26.0 nM | 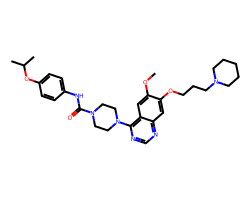 |
| BOSUTINIB | COc1cc(Nc2c(C#N)cnc3cc(OCCCN4CCN(C)CC4)c(OC)cc23)c(Cl)cc1Cl | IC50: 1.3 nM | 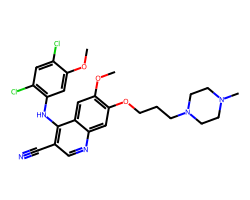 |
| VANDETANIB | COc1cc2/c(=N/c3ccc(Br)cc3F)nc[nH]c2cc1OCC1CCN(C)CC1 | IC50: 900.0 nM | 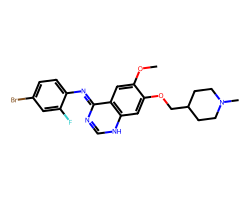 |
| ERLOTINIB | C#Cc1cccc(Nc2ncnc3cc(OCCOC)c(OCCOC)cc23)c1 | IC50: 1450.0 nM | 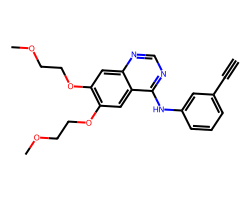 |
| VORINOSTAT | O=C(CCCCCCC(=O)Nc1ccccc1)NO | Inhibition: 100.0 % | 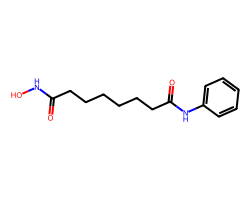 |
| RUBOXISTAURIN | CN(C)C[C@@H]1CCn2cc(c3ccccc32)C2=C(C(=O)NC2=O)c2cn(c3ccccc23)CCO1 | IC50: 300.0 nM | 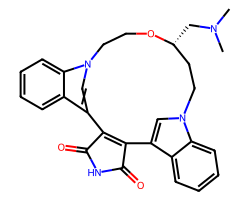 |
| MOTESANIB | CC1(C)CNc2cc(NC(=O)c3cccnc3NCc3ccncc3)ccc21 | Kd: 1100.0 nM | 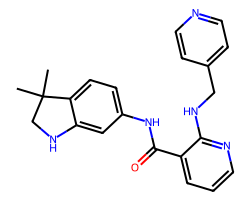 |
| SUNITINIB | CCN(CC)CCNC(=O)c1c(C)[nH]c(/C=C2\C(=O)Nc3ccc(F)cc32)c1C | IC50: 80.0 nM | 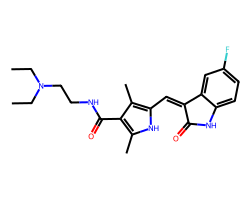 |
| AZD-1152-HQPA | CCN(CCO)CCCOc1ccc2c(Nc3cc(CC(=O)Nc4cccc(F)c4)[nH]n3)ncnc2c1 | Ki: 10000.0 nM | 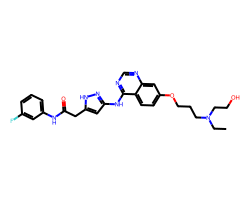 |
| QUERCETIN | O=c1c(O)c(-c2ccc(O)c(O)c2)oc2cc(O)cc(O)c12 | IC50: 32870.0 nM | 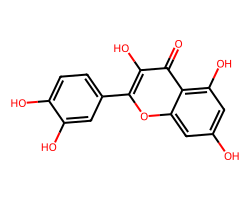 |
| LINIFANIB | Cc1ccc(F)c(NC(=O)Nc2ccc(-c3cccc4[nH]nc(N)c34)cc2)c1 | IC50: 4.0 nM | 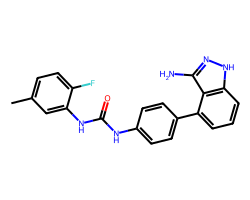 |
| LAPATINIB | CS(=O)(=O)CCNCc1ccc(-c2ccc3ncnc(Nc4ccc(OCc5cccc(F)c5)c(Cl)c4)c3c2)o1 | IC50: 10.0 nM | 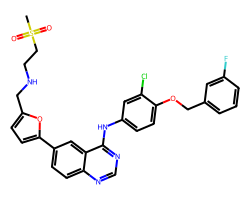 |
| DOVITINIB | CN1CCN(c2ccc3nc(-c4c(N)c5c(F)cccc5[nH]c4=O)[nH]c3c2)CC1 | IC50: 65.0 nM | 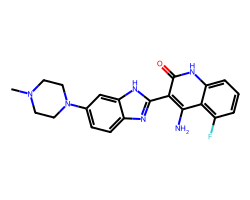 |
| CRIZOTINIB | C[C@@H](Oc1cc(-c2cnn(C3CCNCC3)c2)cnc1N)c1c(Cl)ccc(F)c1Cl | IC50: 8.0 nM | 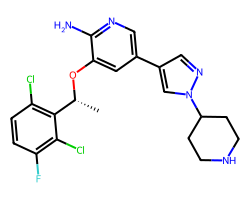 |
| PAZOPANIB | Cc1ccc(Nc2nccc(N(C)c3ccc4c(C)n(C)nc4c3)n2)cc1S(N)(=O)=O | IC50: 10.0 nM | 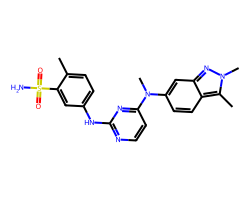 |
| IMATINIB | Cc1ccc(NC(=O)c2ccc(CN3CCN(C)CC3)cc2)cc1Nc1nccc(-c2cccnc2)n1 | IC50: 40.0 nM | 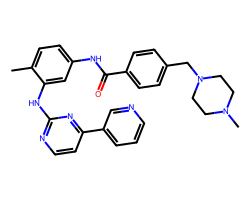 |
| GEFITINIB | COc1cc2ncnc(Nc3ccc(F)c(Cl)c3)c2cc1OCCCN1CCOCC1 | IC50: 515.0 nM | 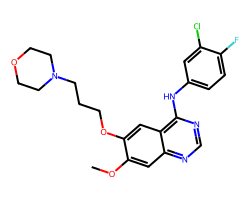 |
| DORAMAPIMOD | Cc1ccc(-n2nc(C(C)(C)C)cc2NC(=O)Nc2ccc(OCCN3CCOCC3)c3ccccc23)cc1 | Kd: 0.046 nM | 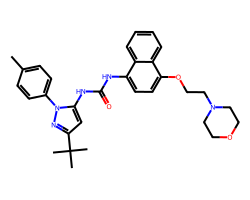 |
| TOZASERTIB | Cc1cc(Nc2cc(N3CCN(C)CC3)nc(Sc3ccc(NC(=O)C4CC4)cc3)n2)n[nH]1 | Ki: 0.6 nM | 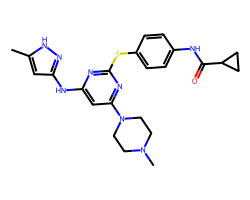 |
| SELICICLIB | CC[C@H](CO)Nc1nc(NCc2ccccc2)c2ncn(C(C)C)c2n1 | IC50: 450.0 nM | 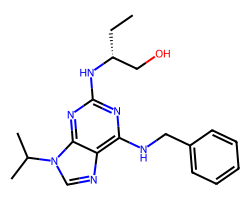 |
| BORTEZOMIB | CC(C)C[C@H](NC(=O)[C@H](Cc1ccccc1)NC(=O)c1cnccn1)B(O)O | Ki: 0.62 nM | 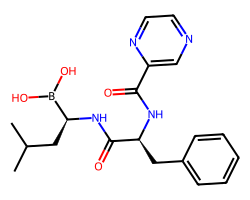 |
| MIDOSTAURIN | CO[C@@H]1[C@H](N(C)C(=O)c2ccccc2)C[C@H]2O[C@]1(C)n1c3ccccc3c3c4c(c5c6ccccc6n2c5c31)C(=O)NC4 | Kd: 11.0 nM | 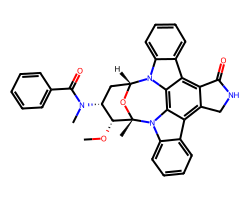 |
| SORAFENIB | CNC(=O)c1cc(Oc2ccc(NC(=O)Nc3ccc(Cl)c(C(F)(F)F)c3)cc2)ccn1 | IC50: 12.0 nM | 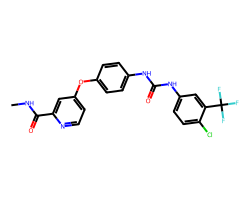 |
| SARACATINIB | CN1CCN(CCOc2cc(OC3CCOCC3)c3c(Nc4c(Cl)ccc5c4OCO5)ncnc3c2)CC1 | IC50: 2.7 nM | 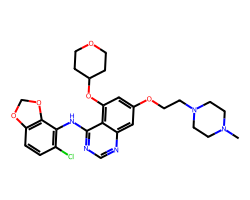 |
| PYRIMETHAMINE | CCc1nc(N)nc(N)c1-c1ccc(Cl)cc1 | IC50: 2800.0 nM | 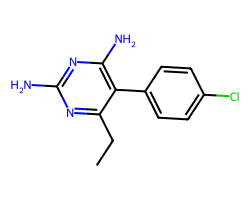 |
Top Fragments
| SMILES | Avg pKi | Count | Structure |
|---|---|---|---|
| [5*]N[5*] | 7.68 | 741 | 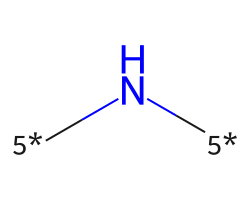 |
| [3*]O[3*] | 7.51 | 429 | 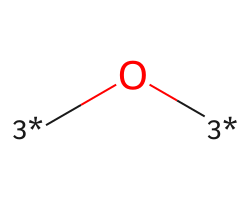 |
| [1*]C([6*])=O | 7.87 | 312 | 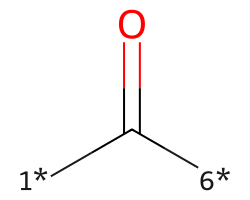 |
| [4*]C[8*] | 6.93 | 273 | 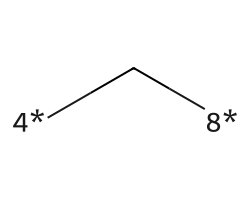 |
| [16*]c1ccc([16*])cc1 | 8.12 | 234 | 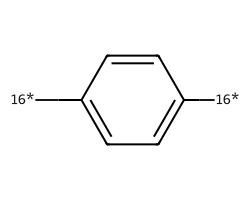 |